· 3 min read
Schritt-für-Schritt-Anleitung zur Ausführung von Stable Video Diffusion (SVD) unter Linux
Stable Video Diffusion (SVD) ist ein Videoerzeugungsmodell, und dieser Artikel bietet eine ausführliche Anleitung zur Ausführung von SVD unter Linux sowie Lösungstipps.
Lassen Sie uns erkunden, wie Sie Stable Video Diffusion (SVD) verwenden, ein benutzerfreundliches Videoerzeugungsmodell, das von Stability AI veröffentlicht wurde und auf der stabilen Diffusion von Bildmodellen basiert. Es stellt sowohl die erforderlichen Modelle als auch Open-Source-Code bereit und ermöglicht es jedem, innerhalb von 20 Sekunden loszulegen.
Offizielle Ressourcen und Webseiten für SVD
- GitHub-Repository: Stability-AI/generative-models
- Hugging Face: stabilityai/stable-video-diffusion-img2vid-xt
- Forschungspapier: Skalierung latenter Video-Diffusionsmodelle auf große Datensätze
Installationsvoraussetzungen
- GPU-Speicheranforderung: Mindestens 16 GB GPU-Speicher.
- RAM-Anforderung: Empfohlen werden 32 GB RAM oder mehr.
Stable Video Diffusion-Code herunterladen
git clone https://github.com/Stability-AI/generative-models
cd generative-modelsOffizielle vortrainierte Modelle für Stable Video Diffusion herunterladen
- SVD: stabilityai/stable-video-diffusion-img2vid-xt
- SVD-XT: stabilityai/stable-video-diffusion-img2vid
Es gibt vier Modelle zur Verfügung, und eines davon kann verwendet werden. Sie sollten im Verzeichnis generative-models/checkpoints/ platziert werden.
Unterschiede der Modelle:
- SVD: Dieses Modell ist darauf trainiert, 14 Frames mit einer Auflösung von 576x1024 basierend auf gleichgroßen Kontextframes zu generieren.
- SVD-XT: Ähnlich wie die SVD-Architektur, aber feinabgestimmt für die Generierung von 25 Bildern. Beachten Sie, dass dies mehr GPU-Speicher und RAM erfordert.
Einrichtung der Python-Umgebung
Es wird empfohlen, eine Python-Umgebung mit conda und Python 3.10 zu erstellen und die SVD-Abhängigkeiten zu installieren.
conda create --name svd python=3.10 -y
source activate svd
pip3 install -r requirements/pt2.txt
pip3 install .Ausführen von Stable Video Diffusion
Wechseln Sie zum SVD-Codeverzeichnis und führen Sie SVD mit Streamlit aus. Sie können die Ausführungsparameter wie --server.port und --server.address anpassen.
cd generative-models
streamlit run scripts/demo/video_sampling.py --server.address 0.0.0.0 --server.port 4801Bei der Ausführung von SVD werden auch zwei Modelle heruntergeladen, models–laion–CLIP-ViT und ViT-L-14. Sie können sie manuell herunterladen und in die folgenden Verzeichnisse kopieren:
/root/.cache/huggingface/hub/models–laion–CLIP-ViT-H-14-laion2B-s32B-b79K
/root/.cache/clip/ViT-L-14.ptDownload-Links:
Wenn Sie den folgenden Inhalt im Terminal sehen, bedeutet dies, dass SVD erfolgreich ausgeführt wurde:
Verwendung von SVD
Öffnen Sie einen Webbrowser und gehen Sie zu http://<ip>:4801. Sie werden die folgende Benutzeroberfläche sehen:
Beginnen Sie mit der Verwendung von Stable Video Diffusion, um Videos zu generieren. Wählen Sie die Modellversion aus und überprüfen Sie:
Ziehen Sie die Bilder, aus denen Sie Videos generieren möchten, in den Bereich Eingabe, klicken Sie dann auf die Schaltfläche Abtasten und warten Sie auf die Generierung des Videos.
Die Generierungsgeschwindigkeit hängt von der Konfiguration Ihres Computers ab. Zum Beispiel dauert es auf einem RTX 3090 etwa 2-3 Minuten, und das generierte Video wird automatisch lokal heruntergeladen.
Erklärung der Parameter-Einstellungen
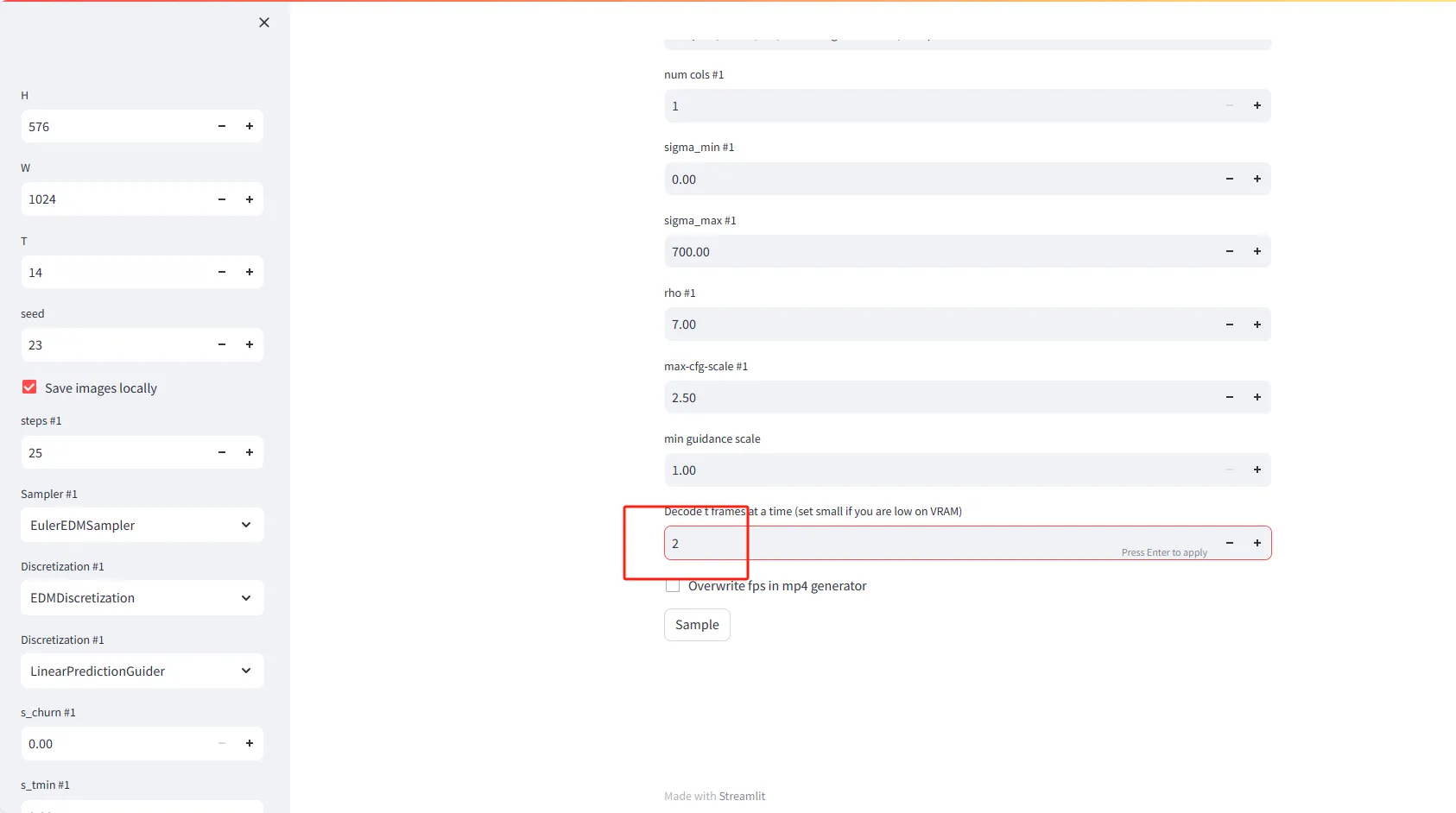
- Höhe (Height): Legen Sie die Höhe der Videoframes in Pixel fest. Standardwert ist 576.
- Breite (Width): Legen Sie die Breite der Videoframes in Pixel fest. Standardwert ist 1024.
- T (Zeit oder Frames): Legen Sie die Anzahl der zu generierenden Frames für das Video fest. Standardwert ist 14.
- Seed: Geben Sie eine Zahl ein, um zufällige, aber reproduzierbare Ergebnisse zu erzeugen. Standardwert ist 23.
- Bilder lokal speichern: Aktivieren Sie diese Option, um die generierten Videoframes lokal zu speichern.
Erweiterte Einstellungen
- **Schritte #1 (Iteration
en)**: Legen Sie die Anzahl der erforderlichen Iterationen fest, um jedes Videoframe zu generieren. Standardwert ist 25.
- Sampler #1: Wählen Sie einen Abtastalgorithmus aus, um die Generierung von Videoframes zu steuern. Die Standardoption ist EulerEDMSampler.
- Diskretisierung #1: Legen Sie die Diskretierungsstrategie fest. Standardmäßig ist EDMDiscretization.
- Diskretisierung #2: Sie können eine zweite Diskretierungsstrategie auswählen, wie zum Beispiel LinearPredictionGuider.
Besondere Funktionen
- T-Frames auf einmal decodieren: Legen Sie die Anzahl der Frames fest, die gleichzeitig im Speicher decodiert werden sollen. Wenn Sie wenig VRAM (Videospeicher) haben, sollten Sie eine kleinere Zahl wie 2 einstellen.
- Framerate in mp4-Generator überschreiben: Aktivieren Sie diese Option, um die Einstellung der Bildrate beim Generieren von mp4-Videodateien zu überschreiben.
Häufige Probleme bei der stabilen Video-Diffusion
No module named 'scripts'
>> from scripts.demo.streamlit_helpers import *
ModuleNotFoundError: No module named 'scripts'Dieser Fehler tritt auf, weil das Verzeichnis generative-models zur Umgebungsvariablen PYTHONPATH hinzugefügt werden muss. Dies kann wie folgt durchgeführt werden:
echo 'export PYTHONPATH=/generative-models:$PYTHONPATH' >> /root/.bashrc
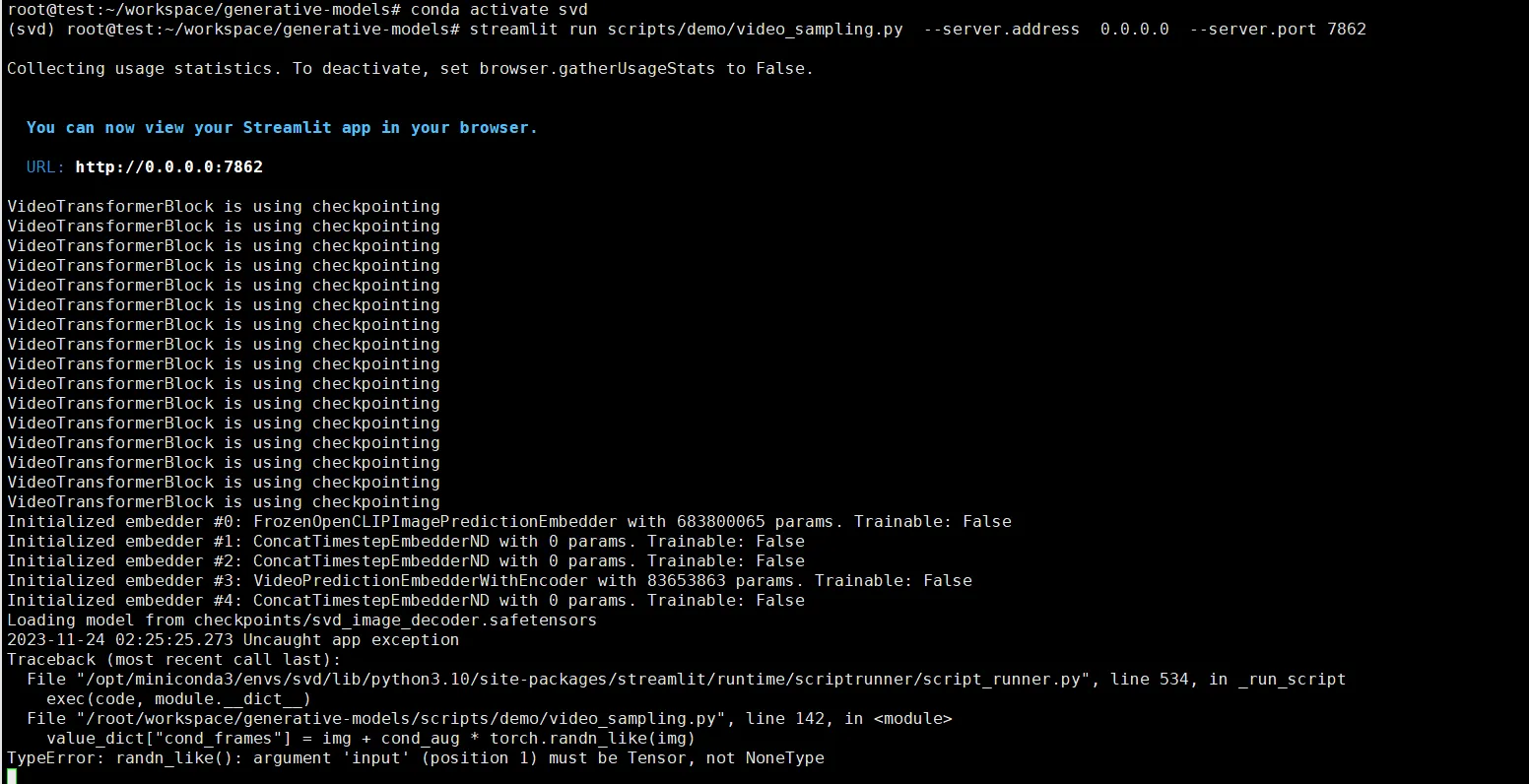
source /root/.bashrcTypeError: randn_like()
value_dict["cond_frames"] = img + cond_aug * torch.randn_like(img)
TypeError: randn_likeDieser Fehler tritt auf, wenn kein Bild zur Generierung ausgewählt wurde. Sie müssen ein Bild hochladen.