· 4 min read
Guide étape par étape pour exécuter Stable Video Diffusion (SVD) sous Linux
Stable Video Diffusion (SVD) est un modèle de génération de vidéos, et cet article fournit un guide détaillé sur l'exécution de SVD sous Linux, ainsi que des conseils pour résoudre les problèmes.
Découvrons comment utiliser Stable Video Diffusion (SVD), un modèle de génération de vidéos convivial publié par Stability AI, basé sur la diffusion stable de modèles d’images. Il fournit à la fois les modèles nécessaires et du code open source, le rendant accessible à tous pour commencer en moins de 20 secondes.
Ressources officielles et pages web pour SVD
- Dépôt GitHub : Stability-AI/generative-models
- Hugging Face : stabilityai/stable-video-diffusion-img2vid-xt
- Article de recherche : Mise à l’échelle des modèles de diffusion vidéo latente sur de grands ensembles de données
Prérequis d’installation
- Exigence en mémoire GPU : Au moins 16 Go de mémoire GPU.
- Exigence en RAM : Recommandé 32 Go de RAM ou plus.
Téléchargement du code Stable Video Diffusion
git clone https://github.com/Stability-AI/generative-models
cd generative-modelsTéléchargement des modèles pré-entraînés officiels pour Stable Video Diffusion
- SVD : stabilityai/stable-video-diffusion-img2vid-xt
- SVD-XT : stabilityai/stable-video-diffusion-img2vid
Il existe quatre modèles disponibles, et l’un d’entre eux peut être utilisé. Ils doivent être placés dans le répertoire generative-models/checkpoints/.
Différences entre les modèles :
- SVD : Ce modèle est formé pour générer 14 images de résolution 576x1024 basées sur des images contextuelles de même taille.
- SVD-XT : Similaire à l’architecture SVD, mais affiné pour générer 25 images. Notez qu’il nécessite plus de mémoire GPU et de RAM.
Configuration de l’environnement Python
Il est recommandé de créer un environnement Python avec conda avec Python 3.10 et d’installer les dépendances SVD.
conda create --name svd python=3.10 -y
source activate svd
pip3 install -r requirements/pt2.txt
pip3 install .Exécution de Stable Video Diffusion
Accédez au répertoire du code SVD et exécutez SVD en utilisant Streamlit. Vous pouvez personnaliser les paramètres d’exécution, tels que --server.port et --server.address.
cd generative-models
streamlit run scripts/demo/video_sampling.py --server.address 0.0.0.0 --server.port 4801Lors de l’exécution de SVD, il téléchargera également deux modèles, models–laion–CLIP-ViT et ViT-L-14. Vous pouvez les télécharger manuellement et les placer dans les répertoires suivants :
/root/.cache/huggingface/hub/models–laion–CLIP-ViT-H-14-laion2B-s32B-b79K
/root/.cache/clip/ViT-L-14.ptLiens de téléchargement :
Lorsque vous voyez le contenu suivant dans le terminal, cela signifie que SVD a été exécuté avec succès :
Utilisation de SVD
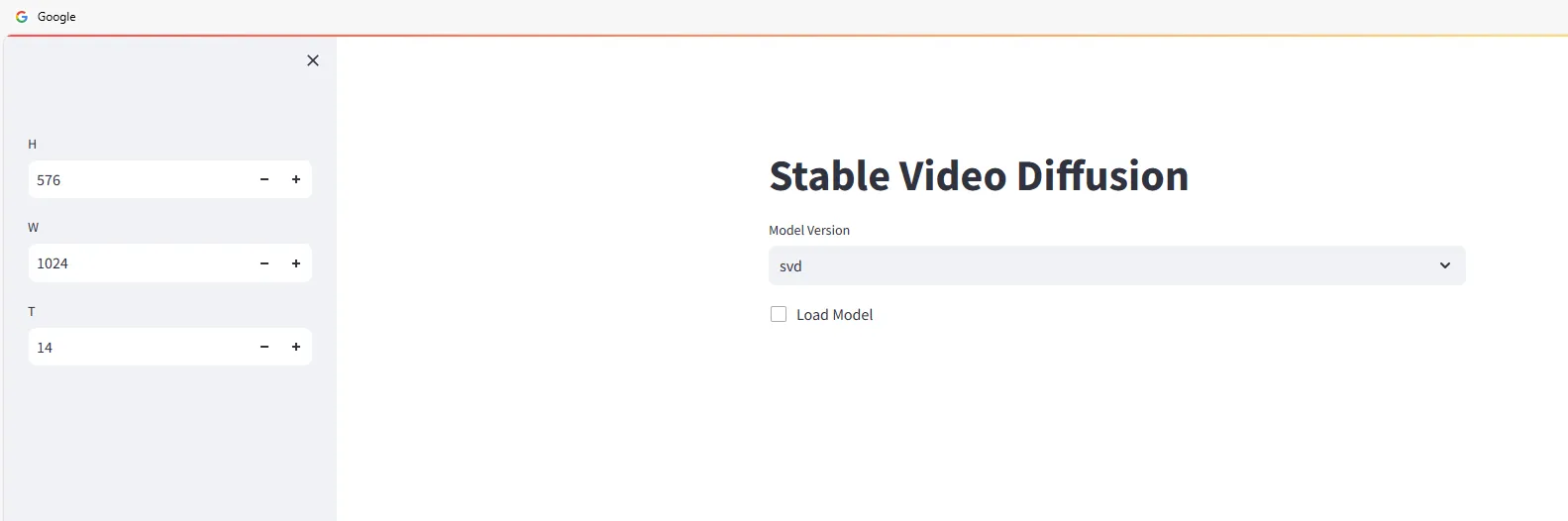
Ouvrez un navigateur web et allez sur http://<ip>:4801. Vous verrez l’interface suivante :
Commencez à utiliser Stable Video Diffusion pour générer des vidéos. Sélectionnez la version du modèle et cochez :
Faites glisser et déposez les images à partir desquelles vous souhaitez générer des vidéos dans la zone Input, puis cliquez sur le bouton Sample et attendez la génération de la vidéo.
La vitesse de génération dépend de la configuration de votre machine. Par exemple, un RTX 3090 prend environ 2 à 3 minutes, et la vidéo générée sera automatiquement téléchargée localement.
Explication des paramètres
- H (Hauteur) : Définissez la hauteur des images vidéo en pixels. La valeur par défaut est 576.
- W (Largeur) : Définissez la largeur des images vidéo en pixels. La valeur par défaut est 1024.
- T (Temps ou Images) : Définissez le nombre d’images à générer pour la vidéo. La valeur par défaut est 14.
- Seed : Entrez un nombre pour obtenir des résultats aléatoires mais reproductibles. La valeur par défaut est 23.
- Enregistrer les images localement : Cochez cette option pour enregistrer localement les images générées de la vidéo.
Paramètres avancés
- Étapes #1 (Itérations) : Définissez le nombre d’itérations nécessaires pour générer chaque image vidéo. La valeur par défaut est 25.
- **Sampler
#1** : Choisissez un algorithme d’échantillonnage pour guider la génération d’images vidéo. L’option par défaut est EulerEDMSampler.
- Discrétisation #1 : Définissez la stratégie de discrétisation. La valeur par défaut est EDMDiscretization.
- Discrétisation #2 : Vous pouvez choisir une deuxième stratégie de discrétisation, telle que LinearPredictionGuider.
Fonctionnalités spéciales
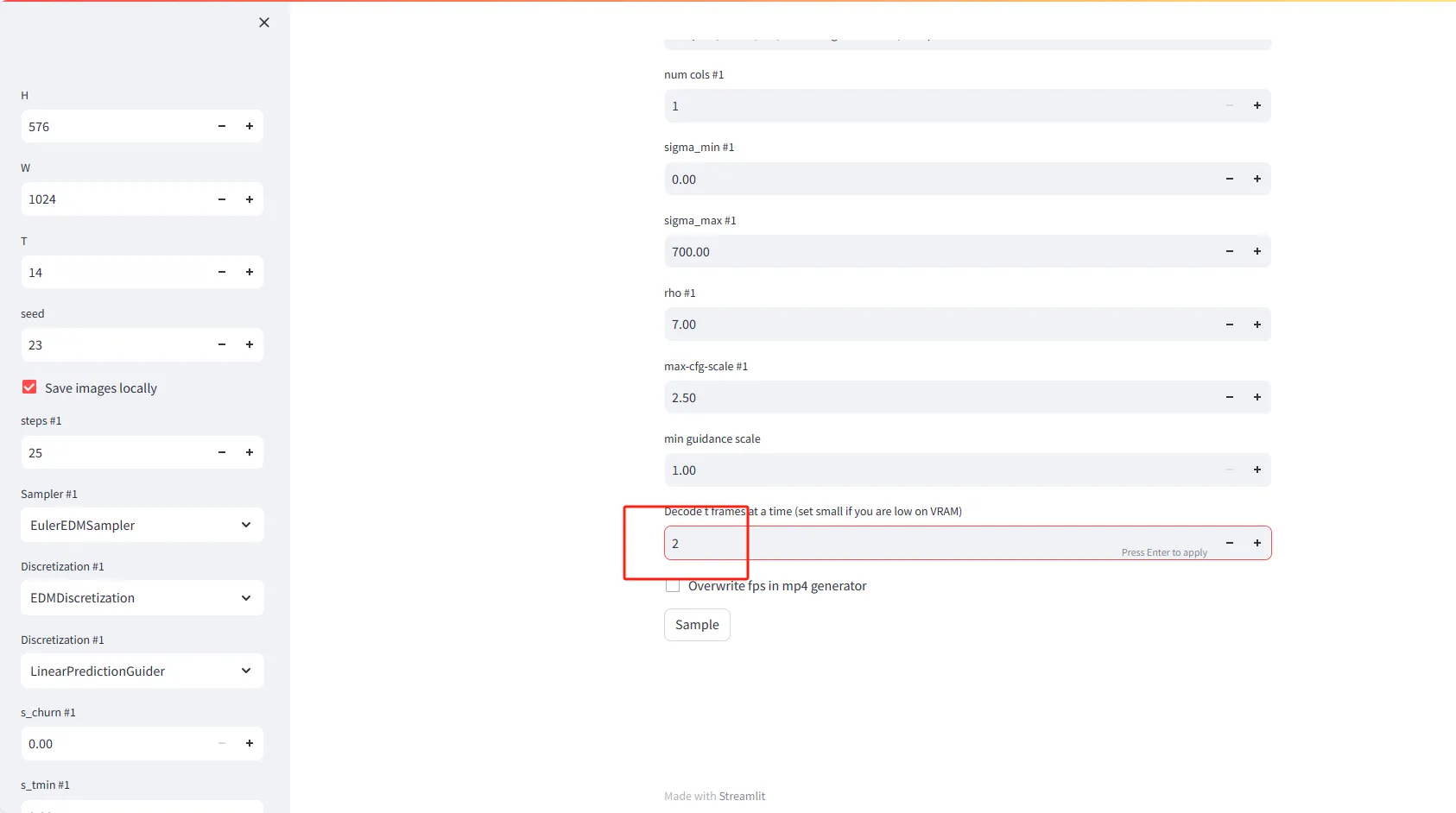
- Décoder t images à la fois : Définissez le nombre d’images à décoder en mémoire à la fois. Si vous disposez de peu de VRAM (mémoire vidéo), envisagez de définir une valeur plus petite, comme 2.
- Écraser le débit d’images dans le générateur mp4 : Cochez cette option pour écraser le paramètre de débit d’images lors de la génération de fichiers vidéo mp4.
Problèmes courants avec Stable Video Diffusion
Aucun module nommé 'scripts'
>> from scripts.demo.streamlit_helpers import *
ModuleNotFoundError: Aucun module nommé 'scripts'Cette erreur se produit car le répertoire generative-models doit être ajouté à la variable d’environnement PYTHONPATH. Vous pouvez le faire comme suit :
echo 'export PYTHONPATH=/generative-models:$PYTHONPATH' >> /root/.bashrc
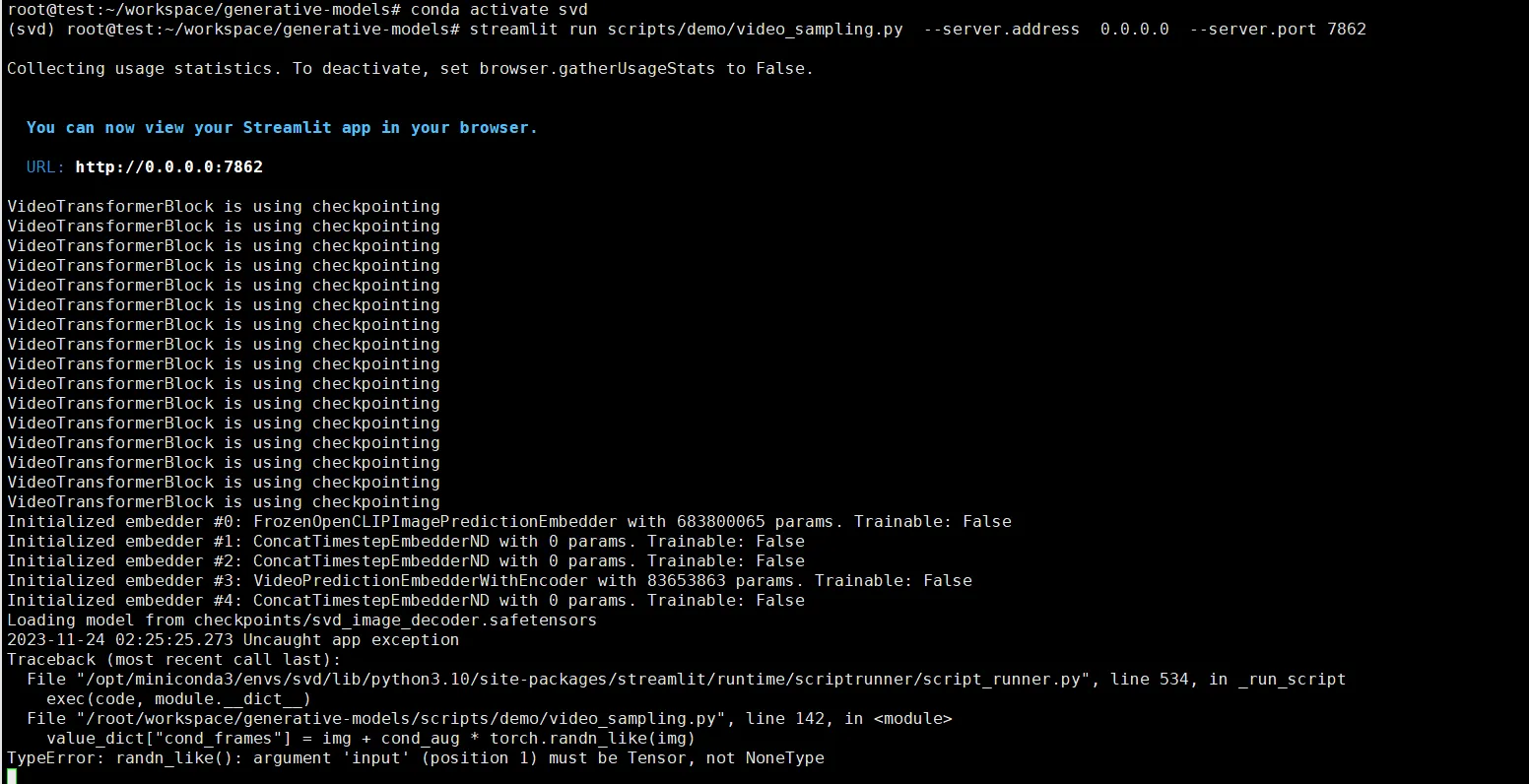
source /root/.bashrcTypeError: randn_like()
value_dict["cond_frames"] = img + cond_aug * torch.randn_like(img)
TypeError: randn_likeCette erreur est due au fait de ne pas avoir sélectionné une image à générer à partir de. Vous devez télécharger une image.