· 4 min read
Guida passo passo all'esecuzione di Stable Video Diffusion (SVD) su Linux
Stable Video Diffusion (SVD) è un modello di generazione video, e questo articolo fornisce una guida dettagliata su come eseguire SVD su Linux insieme a suggerimenti per la risoluzione dei problemi.
Esploriamo come utilizzare Stable Video Diffusion (SVD), un modello di generazione video user-friendly rilasciato da Stability AI, basato sulla diffusione stabile dei modelli di immagine. Fornisce sia i modelli necessari che il codice open-source, rendendolo accessibile a tutti per iniziare entro 20 secondi.
Risorse ufficiali e pagine web per SVD
- Repository GitHub: Stability-AI/generative-models
- Hugging Face: stabilityai/stable-video-diffusion-img2vid-xt
- Articolo di ricerca: Scaling Latent Video Diffusion Models to Large Datasets
Prerequisiti di installazione
- Requisiti di memoria GPU: Almeno 16 GB di memoria GPU.
- Requisiti di RAM: Consigliati 32 GB di RAM o più.
Scaricare il codice di Stable Video Diffusion
git clone https://github.com/Stability-AI/generative-models
cd generative-modelsScaricare i modelli preaddestrati ufficiali per Stable Video Diffusion
- SVD: stabilityai/stable-video-diffusion-img2vid-xt
- SVD-XT: stabilityai/stable-video-diffusion-img2vid
Ci sono quattro modelli disponibili e ognuno di essi può essere utilizzato. Dovrebbero essere posizionati nella directory generative-models/checkpoints/.
Differenze tra i modelli:
- SVD: Questo modello è addestrato per generare 14 fotogrammi a risoluzione 576x1024 basati su fotogrammi contestuali della stessa dimensione.
- SVD-XT: Simile all’architettura SVD ma ottimizzato per generare 25 fotogrammi di immagini. Notare che richiede più memoria GPU e RAM.
Configurazione dell’ambiente Python
Si consiglia di creare un ambiente Python utilizzando conda con Python 3.10 e installare le dipendenze di SVD.
conda create --name svd python=3.10 -y
source activate svd
pip3 install -r requirements/pt2.txt
pip3 install .Esecuzione di Stable Video Diffusion
Passa alla directory del codice di SVD ed esegui SVD utilizzando Streamlit. È possibile personalizzare i parametri di esecuzione, come --server.port e --server.address.
cd generative-models
streamlit run scripts/demo/video_sampling.py --server.address 0.0.0.0 --server.port 4801Durante l’esecuzione di SVD, verranno anche scaricati due modelli, models–laion–CLIP-ViT e ViT-L-14. È possibile scaricarli manualmente e collocarli nelle seguenti directory:
/root/.cache/huggingface/hub/models–laion–CLIP-ViT-H-14-laion2B-s32B-b79K
/root/.cache/clip/ViT-L-14.ptCollegamenti per il download:
Quando vedi il seguente contenuto nel terminale, indica che SVD è stato eseguito con successo:
Utilizzo di SVD
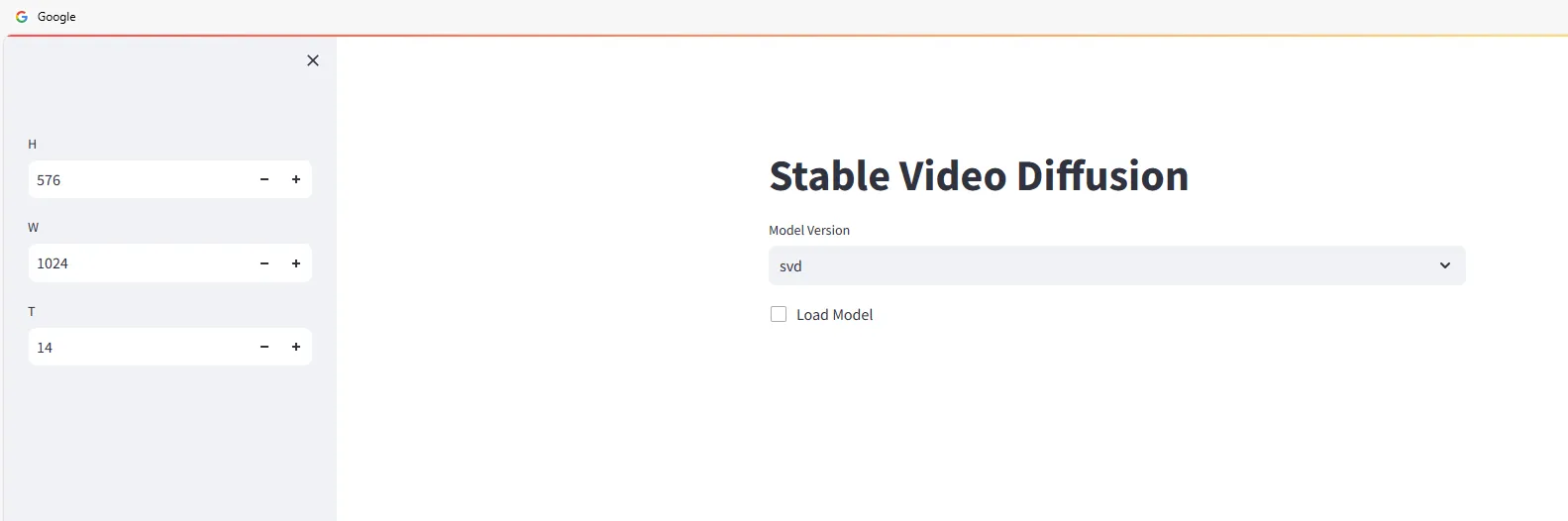
Apri un browser web e vai su http://<ip>:4801. Vedrai l’interfaccia seguente:
Inizia a utilizzare Stable Video Diffusion per generare video. Seleziona la versione del modello e verifica:
Trascina e rilascia le immagini da cui desideri generare i video nell’area Input, quindi clicca sul pulsante Sample e attendi la generazione del video.
La velocità di generazione dipende dalla configurazione del tuo computer. Ad esempio, una RTX 3090 richiede circa 2-3 minuti e il video generato verrà scaricato automaticamente in locale.
Spiegazione delle impostazioni dei parametri
- H (Altezza): Imposta l’altezza dei fotogrammi video in pixel. Il valore predefinito è 576.
- W (Larghezza): Imposta la larghezza dei fotogrammi video in pixel. Il valore predefinito è 1024.
- T (Tempo o Fotogrammi): Imposta il numero di fotogrammi da generare per il video. Il valore predefinito è 14.
- Seed: Inserisci un numero per produrre risultati casuali ma riproducibili. Il valore predefinito è 23.
- Salva le immagini in locale: Seleziona questa opzione per salvare i fotogrammi video generati in locale.
Impostazioni avanzate
- Steps #1 (Iterazioni): Imposta il numero di iterazioni necessarie per generare ciascun fot
ogramma video. Il valore predefinito è 25.
- Sampler #1: Scegli un algoritmo di campionamento per guidare la generazione dei fotogrammi video. L’opzione predefinita è EulerEDMSampler.
- Discretization #1: Imposta la strategia di discretizzazione. Il predefinito è EDMDiscretization.
- Discretization #2: Puoi scegliere una seconda strategia di discretizzazione, come LinearPredictionGuider.
Funzionalità speciali
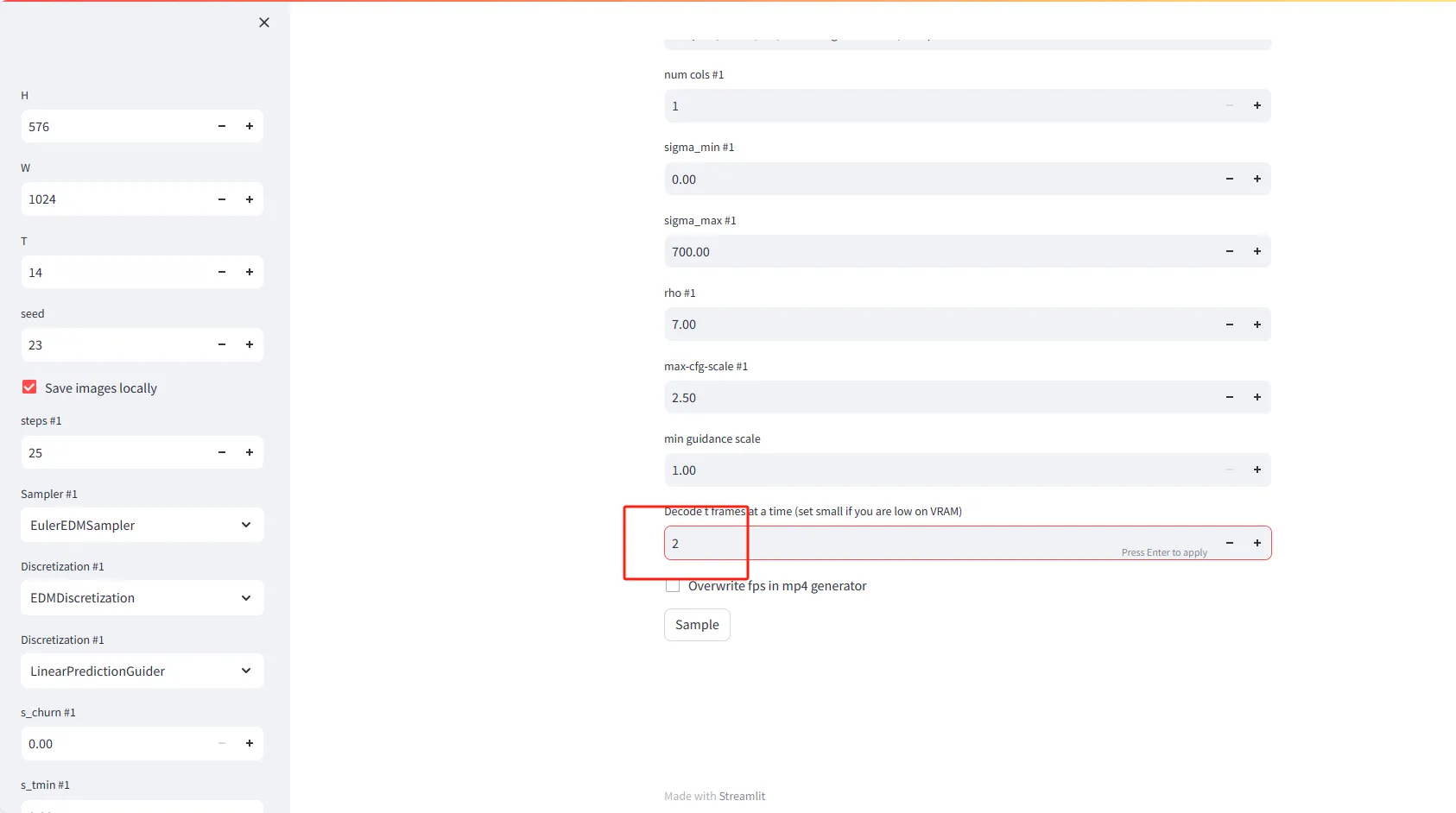
- Decodifica t fotogrammi alla volta: Imposta il numero di fotogrammi da decodificare contemporaneamente in memoria. Se hai una bassa VRAM (Video RAM), considera di impostare un valore più piccolo, ad esempio 2.
- Sovrascrivi il frame rate nel generatore mp4: Seleziona questa opzione per sovrascrivere l’impostazione del frame rate durante la generazione dei file video mp4.
Problemi comuni con Stable Video Diffusion
No module named 'scripts'
>> from scripts.demo.streamlit_helpers import *
ModuleNotFoundError: No module named 'scripts'Questo errore si verifica perché la directory generative-models deve essere aggiunta alla variabile d’ambiente PYTHONPATH. Puoi farlo nel seguente modo:
echo 'export PYTHONPATH=/generative-models:$PYTHONPATH' >> /root/.bashrc
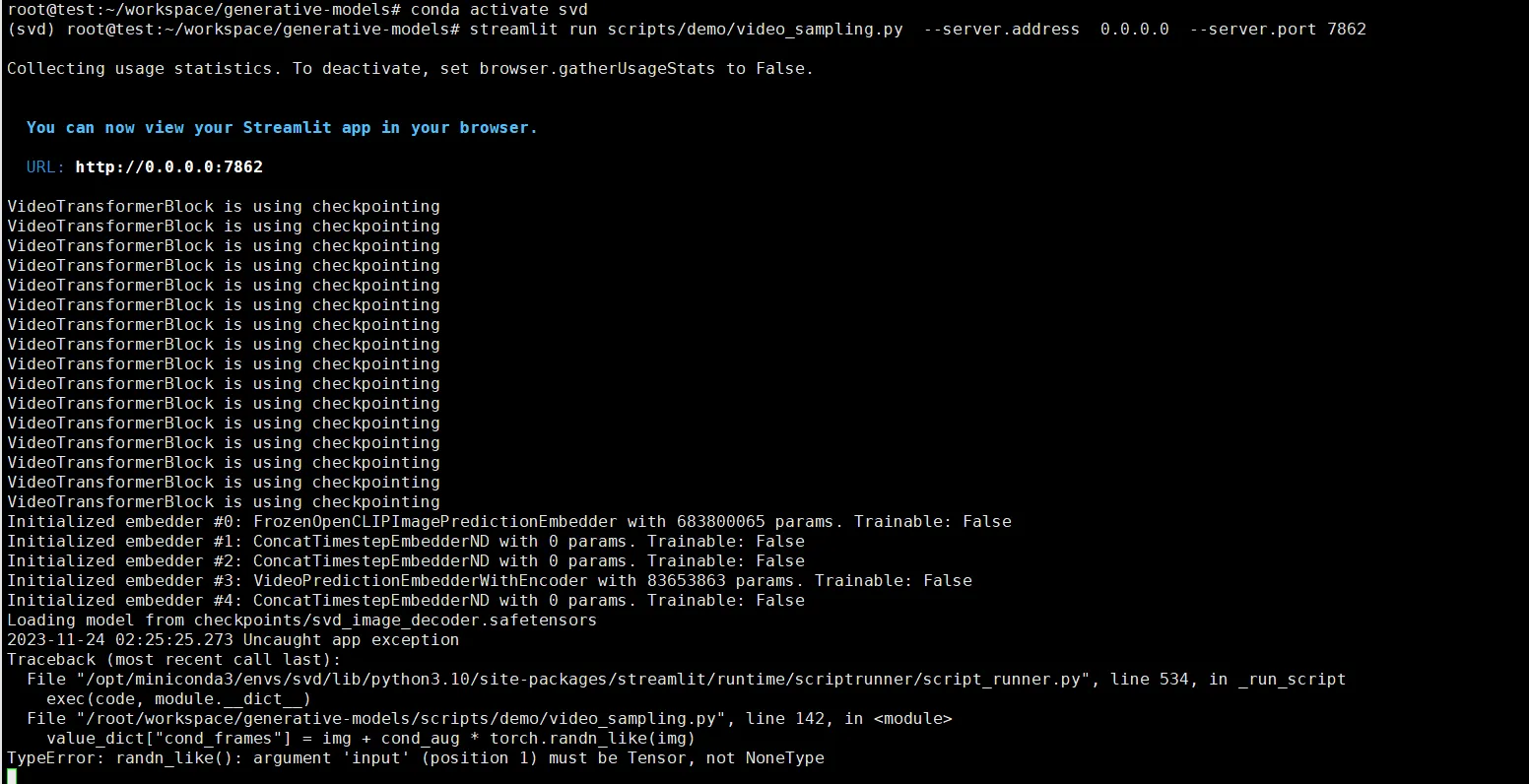
source /root/.bashrcTypeError: randn_like()
value_dict["cond_frames"] = img + cond_aug * torch.randn_like(img)
TypeError: randn_likeQuesto errore è dovuto alla mancata selezione di un’immagine da cui generare. È necessario caricare un’immagine.