· 6 min read
LinuxでStable Video Diffusion(SVD)を実行する手順ガイド
Stable Video Diffusion(SVD)はビデオを生成するモデルで、この記事ではLinuxでSVDを実行する詳細な手順と問題解決方法を紹介します。
Stable Video Diffusion(SVD)の使い方を簡単に紹介しましょう。Stable Video Diffusionは、Stability AIによってリリースされた、画像モデルを安定して拡散させるビデオ生成モデルです。現在、このモデルとオープンソースコードが提供されており、誰でも20秒で簡単に始めることができます。
SVD 公式リソースとウェブサイト
- GitHub | https://github.com/Stability-AI/generative-models
- Hugging Face | https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
- 論文 | https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets
インストールの準備
- VRAM要件:少なくとも16GBのVRAM
- メモリ要件:32GB以上のメモリが推奨されます
Stable Video Diffusionのコードをダウンロード
git clone https://github.com/Stability-AI/generative-models
cd generative-modelsStable Video Diffusionの公式プリトレーニングモデルをダウンロード
- SVD | https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
- SVD-XT | https://huggingface.co/stabilityai/stable-video-diffusion-img2vid
モデルは4つ提供されており、いずれかを使用できます。保存先ディレクトリ:generative-models/checkpoints/
モデルの違い:SVD-XTはSVDの拡張バージョンで、より大きな画像サイズをサポートしますが、より多くのVRAMとメモリが必要です。
SVD: このモデルは、同じサイズのコンテキストフレームに基づいて、576x1024の解像度を持つ14フレームの画像を生成できるようにトレーニングされています。
SVD-XT: SVDのアーキテクチャと同じですが、25フレームの画像生成用に微調整されています。
Python環境の準備
Python環境を作成するためにcondaを使用することをお勧めし、Python 3.10をインストールし、SVDの依存パッケージをインストールします。
conda create --name svd python=3.10 -y
source activate svd
pip3 install -r requirements/pt2.txt
pip3 install .Stable Video Diffusionの実行
 SVDのコードディレクトリに移動し、streamlitを使用してSVDを実行します。
SVDのコードディレクトリに移動し、streamlitを使用してSVDを実行します。--server.port、--server.addressなどの実行パラメータをカスタマイズできます。
cd generative-models
streamlit run scripts/demo/video_sampling.py --server.address 0.0.0.0 --server.port 4801SVDを実行すると、models–laion–CLIP-ViTとViT-L-14の2つのモデルがダウンロードされます。これらを手動で以下のディレクトリに保存できます:
/root/.cache/huggingface/hub/models–laion–CLIP-ViT-H-14-laion2B-s32B-b79K
/root/.cache/clip/ViT-L-14.ptダウンロードリンク
以下の内容がターミナルに表示されると、SVDが正常に実行されていることを示します。
SVDの使用
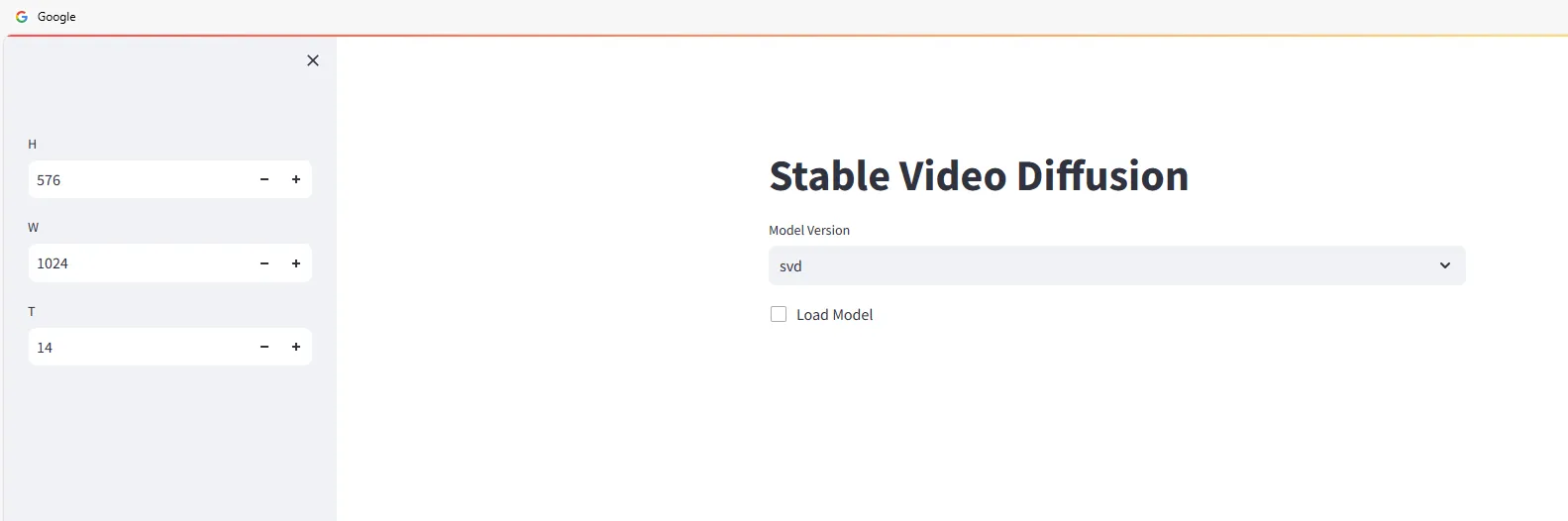
ブラウザで http://<ip>:4801 を開くと、次の画面が表示されます。
Stable Video Diffusionを使用してビデオを生成するために、モデルバージョンを選択し、チェックボックスをオンにします。
ビデオを生成したい画像を「Input」エリアにドラッグ&ドロップし、[Sample]ボタンをクリックしてビデオ生成を待ちます。
マシンの設定に応じて速度が異なります
が、RTX 3090の場合、約2〜3分かかり、生成されたビデオは自動的にローカルにダウンロードされます。
パラメータの設定説明
- H(高さ): ビデオフレームの高さ(ピクセル単位)を設定します。デフォルト値は576です。
- W(幅): ビデオフレームの幅(ピクセル単位)を設定します。デフォルト値は1024です。
- T(時間またはフレーム数): 生成するビデオフレーム数を設定します。デフォルト値は14です。
- seed(シード): ランダムかつ再現可能な結果を生成するために、数字を入力します。デフォルト値は23です。
- Save images locally(ローカルに画像を保存): このオプションを選択すると、生成されたビデオフレームがローカルに保存されます。
高度な設定
- steps #1(ステップ数): 各ビデオフレームの生成に必要な反復ステップ数を設定します。デフォルト値は25です。
- Sampler #1(サンプラー): ビデオフレームの生成をガイドするサンプリングアルゴリズムを選択します。デフォルトはEulerEDMSamplerです。
- Discretization #1(離散化): 離散化戦略を設定します。デフォルトはEDMDiscretizationです。
- Discretization #1(離散化): 第二の離散化戦略を選択することもできます。例:LinearPredictionGuider。
特別な機能
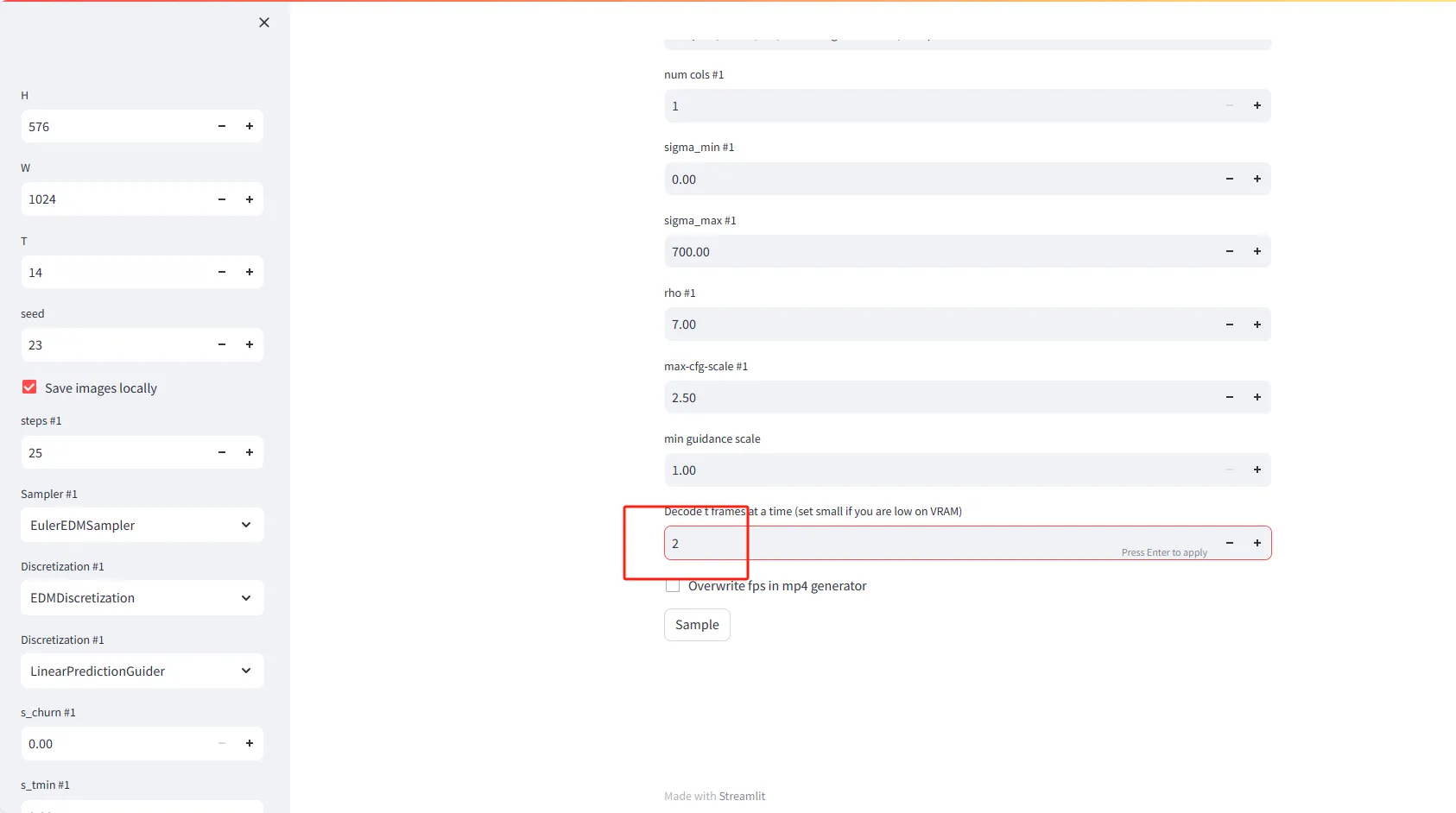
- Decode t frames at a time(tフレームを一度にデコード): メモリ内で一度にデコードするフレーム数を設定します。VRAM(ビデオメモリ)が少ない場合、小さな値(例:2)を設定してください。
- Overwrite fps in mp4 generator(mp4ジェネレーターのfpsを上書き): このオプションを選択すると、mp4ビデオファイルのフレームレート設定が上書きされます。
Stable Video Diffusionの一般的な問題
No module named 'scripts'
>> from scripts.demo.streamlit_helpers import *
ModuleNotFoundError: No module named 'scripts'PYTHONPATH環境変数にgenerative-modelsディレクトリを追加する必要があります。次のように行います:
RUN echo 'export PYTHONPATH=/generative-models:$PYTHONPATH' >> /root/.bashrc
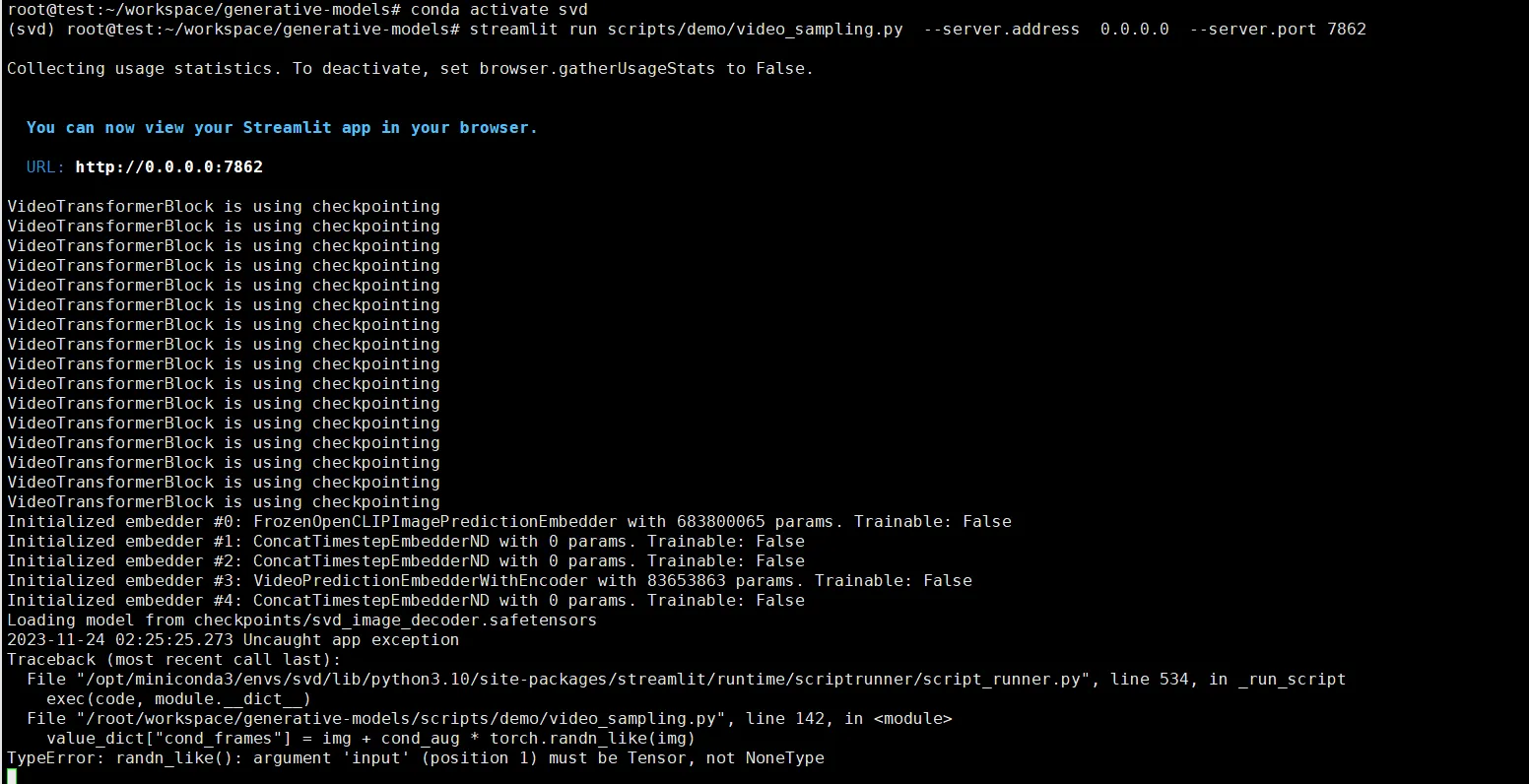
source /root/.bashrcTypeError: randn_like()
value_dict["cond_frames"] = img + cond_aug * torch.randn_like(img)
TypeError: randn_like(): argument 'input' (position 1) must be Tensor, not NoneTypeこのエラーは画像を選択しなかったために発生します。画像をアップロードする必要があります。