· 5 min read
运行 Stable Video Diffusion (SVD) 在 Linux 上的步骤指南
Stable Video Diffusion (SVD) 是一个生成视频的模型,本文是一个在 Linux 上运行 SVD 的详细步骤与问题解决。
让我们介绍简单易上手的Stable Video Diffusion的使用方式。它是由Stability AI发布的,一个基于图像模型稳定扩散的生成视频模型。目前它已经提供了相应的模型和开源代码,每个人都可以在20秒内简单上手。
SVD官方资源与网页
- github | https://github.com/Stability-AI/generative-models
- Hugging Face | https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
- Paper | https://stability.ai/research/stable-video-diffusion-scaling-latent-video-diffusion-models-to-large-datasets
安装准备
- 显存要求:至少16GB显存
- 内存要求:建议32GB内存以上
下载Stable Video Diffusion代码
git clone https://github.com/Stability-AI/generative-models
cd generative-models下载Stable Video Diffusion官方预训练模型
- SVD | https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
- SVD-XT | https://huggingface.co/stabilityai/stable-video-diffusion-img2vid
模型有4个,任意一个都可以使用,存放目录:generative-models/checkpoints/
模型区别:SVD-XT是SVD的扩展版本,支持更大的图像尺寸,但是需要更多的显存和内存。
SVD: 这个模型经过训练,能够根据相同尺寸的上下文帧生成14帧分辨率为576x1024的图像。
SVD-XT: 与SVD架构相同,但经过微调,用于生成25帧图像。
python环境准备
推荐使用conda创建python环境,安装python3.10,安装SVD依赖包
conda create --name svd python=3.10 -y
source activate svd
pip3 install -r requirements/pt2.txt
pip3 install .运行Stable Video Diffusion
 切换到SVD代码目录,并使用streamlit运行SVD, 你可以自定义运行参数,例如
切换到SVD代码目录,并使用streamlit运行SVD, 你可以自定义运行参数,例如--server.port,--server.address等
cd generative-models
streamlit run scripts/demo/video_sampling.py --server.address 0.0.0.0 --server.port 4801当运行SVD时,还会下载两个模型models–laion–CLIP-ViT与ViT-L-14,你可以手动去下载,放到以下目录:
/root/.cache/huggingface/hub/models–laion–CLIP-ViT-H-14-laion2B-s32B-b79K
/root/.cache/clip/ViT-L-14.pt下载链接
当你看到终端输出以下内容时,说明SVD已经运行成功了。
使用SVD
浏览器打开http://<ip>:4801,你会看到以下界面。
开始使用Stable Video Diffusion生成视频, 选择模型版本,然后打勾
将需要生成视频的图片拖拽到Input区域,然后点击Sample按钮,等待生成视频
速度看机器配置,RTX 3090需要2-3分钟左右,生成的视频会自动下载到本地。
参数设置说明
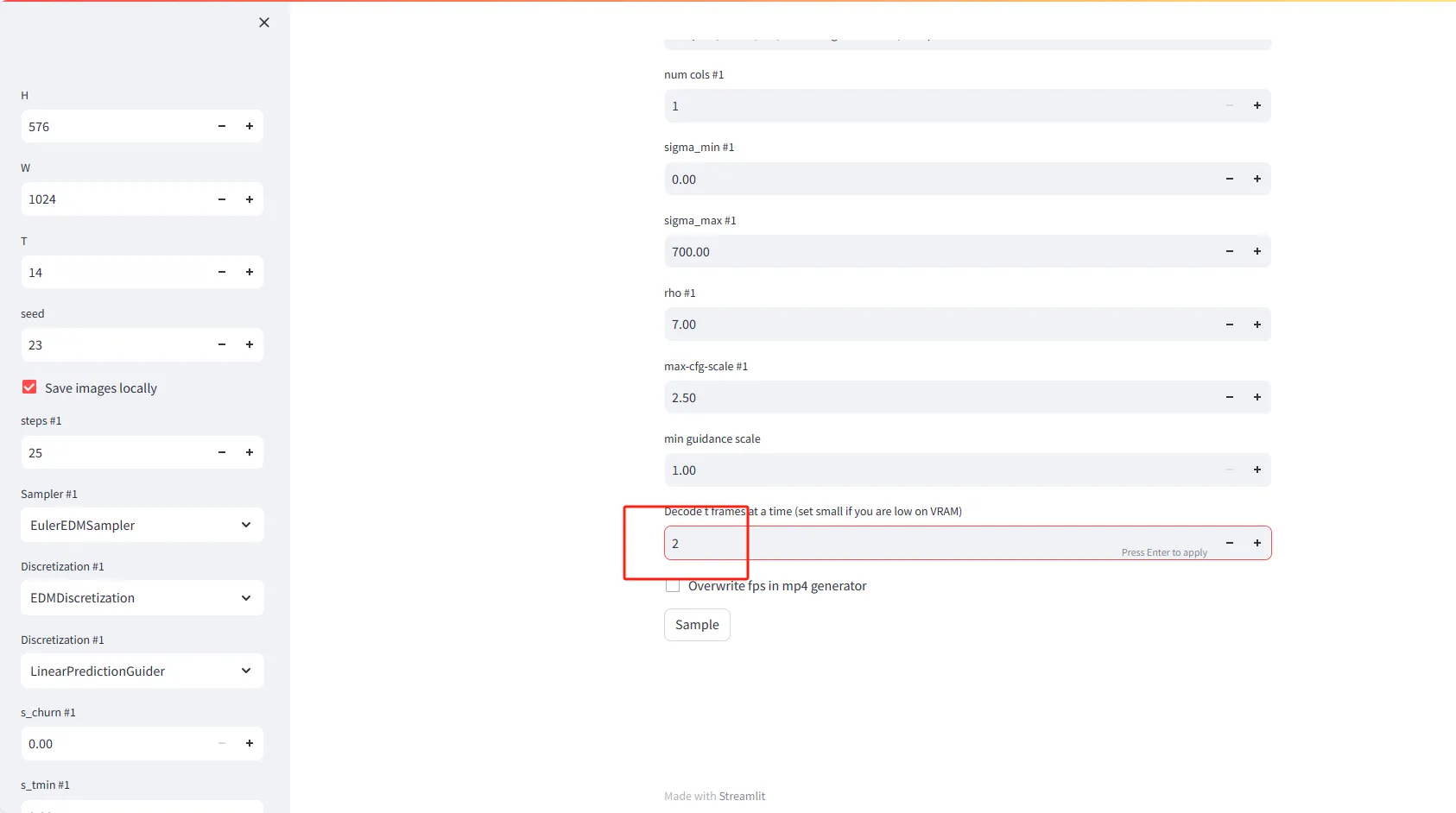
- H(高度): 设置视频帧的高度(以像素为单位)。默认值为576。
- W(宽度): 设置视频帧的宽度(以像素为单位)。默认值为1024。
- T(时间或帧数): 设置要生成的视频帧数。默认值为14。
- seed(种子): 输入一个数字以产生随机但可重复的结果。默认值为23。
- Save images locally(本地保存图像): 勾选此选项将在本地保存生成的视频帧。
高级设置
- steps #1(步骤数): 设置生成每帧视频所需的迭代步骤数。默认值为25。
- Sampler #1(采样器): 选择一个采样算法来指导视频帧的生成。默认选项为EulerEDMSampler。
- Discretization #1(离散化): 设置离散化策略。默认为EDMDiscretization。
- Discretization #1(离散化): 可以选择第二个离散化策略,如LinearPredictionGuider。
特殊功能
- Decode t frames at a time(一次解码t帧): 设置在内存中一次解码的帧数。如果VRAM(视频内存)较低,请设置较小的值,比如2。
- Overwrite fps in mp4 generator(覆盖mp4生成器中的fps): 勾选此选项将在生成mp4视频文件时覆盖帧率设置。
Stable Video Diffusion常见问题
No module named 'scripts'
>> from scripts.demo.streamlit_helpers import *
ModuleNotFoundError: No module named 'scripts'需要将generative-models目录加入到PYTHONPATH环境变量中,例如:
RUN echo 'export PYTHONPATH=/generative-models:$PYTHONPATH' >> /root/.bashrc
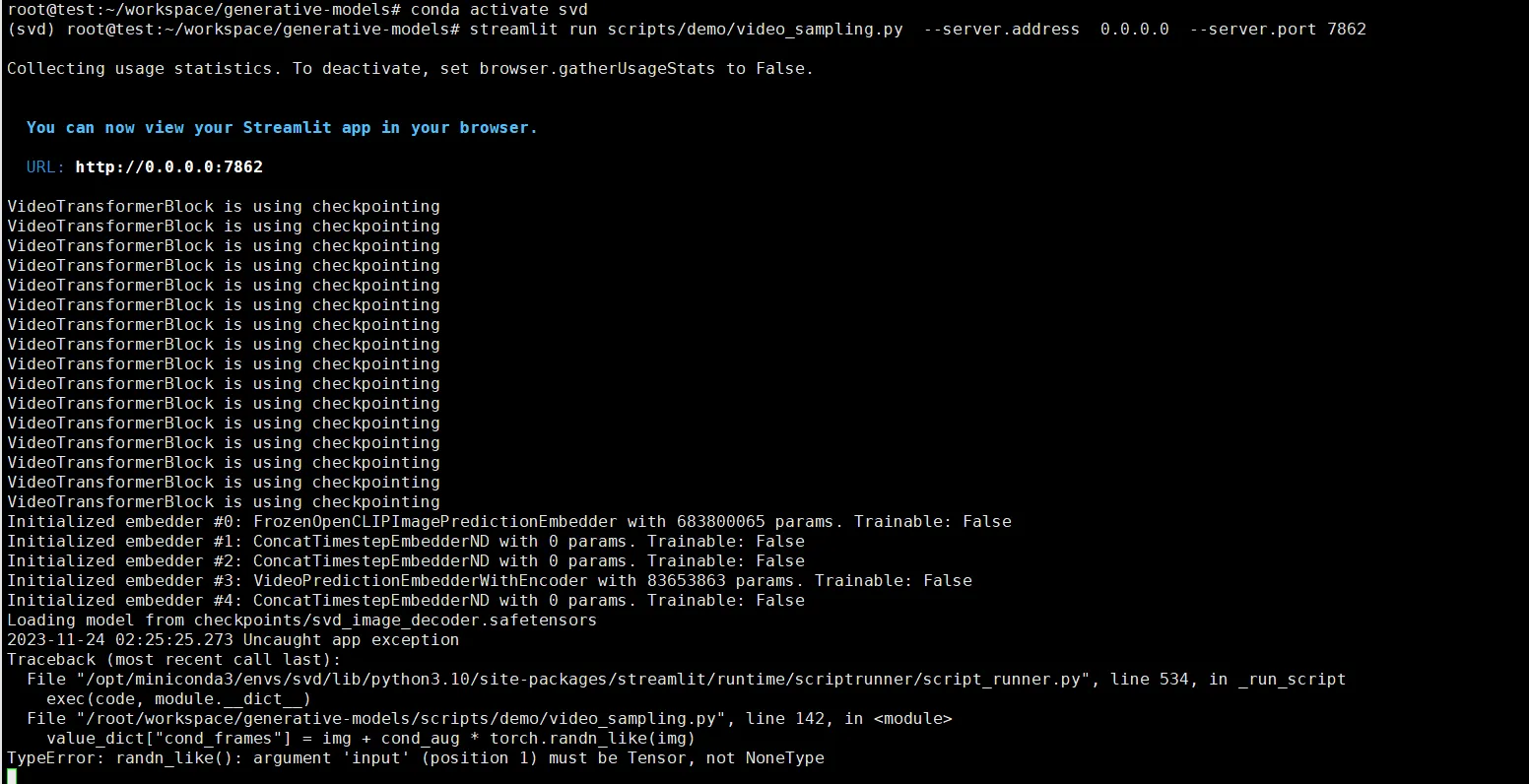
source /root/.bashrcTypeError: randn_like()
value_dict["cond_frames"] = img + cond_aug * torch.randn_like(img)
TypeError: randn_like(): argument 'input' (position 1) must be Tensor, not NoneType这个报错是因为我们没有选择图片的缘故,需要上传图片。